First AWK script
I have been aware of AWK as a "general purpose programming language that is designed for processing text-based data" since college. But until today I never sat down to learn how to use it.
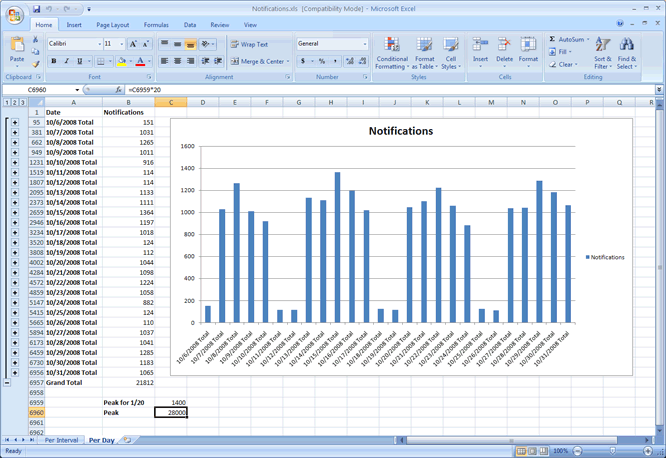
I had a log file that I needed to glean some information from, and turn into Excel spreadsheets with graphs. Here is what the text file looked like:
127: "Information","web-8","10/06/08","17:40:35","BHSTAFFING","Template RunScheduledTask2 has completed sucessfuly. 1 Messages(s) Sent - Execution Time: 0.24 (min)" 134: "Information","web-10","10/06/08","17:45:31","BHSTAFFING","Template RunScheduledTask2 has completed sucessfuly. 5 Messages(s) Sent - Execution Time: 0.18 (min)" 137: "Information","web-7","10/06/08","17:50:27","BHSTAFFING","Template RunScheduledTask2 has completed sucessfuly. 1 Messages(s) Sent - Execution Time: 0.12 (min)" 143: "Information","web-10","10/06/08","17:55:29","BHSTAFFING","Template RunScheduledTask2 has completed sucessfuly. 4 Messages(s) Sent - Execution Time: 0.14 (min)" 146: "Information","web-10","10/06/08","18:00:26","BHSTAFFING","Template RunScheduledTask2 has completed sucessfuly. 1 Messages(s) Sent - Execution Time: 0.09 (min)" ...
What I wanted was a comma delimited file with date, time and message count. With some trial and error, and a lot of help from the official AWK manual, I was able to come up with the following command-line script:
gawk "BEGIN { FS=\",\" }; {sub(/^.*\. /, \"\", $6); sub(/ .*/, \"\", $6); print $3 \",\" $4 \",\" $6}" input.txt > output.txt
Viola! Nice clean CSV data. The code sets the column delimiter to a comma, replaces everything before the space and after the next space in column 6 (using a regex), and then prints out columns 3, 4 and 6 with commas between. This was using gawk, an open-source GNU licensed implementation with a windows port.
10/6/2008,16:10:54,5 10/6/2008,16:15:47,7 10/6/2008,16:20:51,7 10/6/2008,16:25:47,15 10/6/2008,16:30:51,5
Finally, the Excel graph in all it's glory: