
HBase Schema Introduction for Programmers
Schema design in NoSQL is very different from schema design in a RDBMS. Once you get something like HBase up and running, you may find yourself staring blankly at a shell, lost in the possibilities of creating your first table.
You’re probably used to thinking of tables like this:
| rowkey | title | url | clicks | clicks_twitter | clicks_facebook |
|---|---|---|---|---|---|
| fcb75-bit.ly/Z0pngZ | Some Page | http://www.example.com | 16 | 13 | 3 |
| fb499-bit.ly/15C2TLF | null | null | 1 | null | null |
In HBase, this is actually modelled like this:
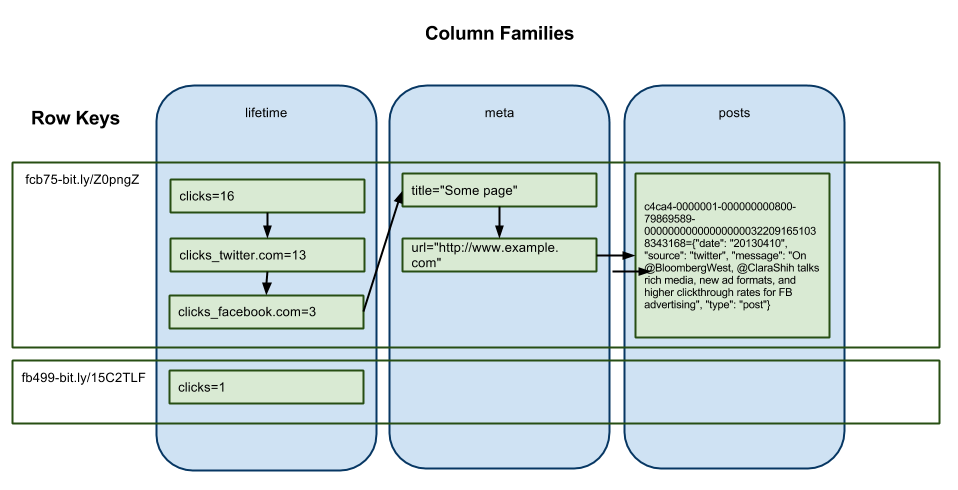
Notice that each row is basically a linked list, ordered by column family and then column name. This is how it’s laid down on disk, as well. Missing columns are free, because there is no space on disk pre-allocated to a null column. Given that, it’s reasonable to design a schema where rows have hundreds or thousands of columns.
Just as columns are laid down on disk like a linked list, so too are rows. They are put on disk in order by row key. Because row keys can by any collection of bytes, ordering of row keys is lexicographical, aka alphabetical. This is in contrast to most RDBMS, where rowkeys are integers and ordered as such.
Consider the following row key order: 1 < 256 < 43 < 7. The row key 265 is actually before 43, because 2 comes before 4. This is why it’s common in HBase to make at least parts of your row key fixed width, ex: 00000001 < 00000007 < 00000043 < 00000256. However, now we have another problem known as hot spotting.
If all your row keys start with the same value, then they will all be going to the same region, and thus the same server. This could easily happen for monotonically increasing row keys, such as traditional RDBMS auto-incrementing PKs, or for timestamps. This can cause all the load for a big write job to block waiting for a single region server, versus spreading out the writes to the whole cluster. A common way to avoid this is to prefix row keys, for example by the md5 hash of the customer ID.
Rows can most efficiently be read back by scanning for consecutive blocks. Say you have a table with a rowkey of customer-date-user. You can easily read back all the data for a given customer and date range using the prefix customer-first-part-of-date, but you can’t easily read back dates ranges for all users at once without scanning all the rows. If you reverse the row key and use customer-user-date, you have the reverse problem. So you want to think about what your primary read pattern is going to be when designing your keys.
Say your primary read patten is going to be reading off the most recent rows. Depending on the format of the dates in your row keys, you may end up with the more recent data at the end of the table. For example: 20130101 > 20130102 > 20130303. Instead, a common pattern is to invert your dates, such as 79869898 > 79869897 > 798698986. This may not apply if you will know at run time the range of values that will be the most recent, i.e. the last 30 days.
For more about HBase schema design, I recommend the online HBase Reference Book, as well as the excellent HBase: The Definitive Guide.