
High availability via client libraries versus dedicated services
Some newer storage technologies allow you to connect to one of a set of servers right from their client library. For example, MongoDB lets you specify one host in a replica set. If that replica becomes unavailable, the client will try to connect to another replica in the same set automatically. Likewise, all memcached clients allow you to specify a whole list of connect strings. If one host is down, the cache lookups for that host will automatically start going to another server. Both of these are examples of high availability by client library.
For MongoDB and memcached in particular, there are features of the platform that make specific load balancing logic desirable. For MongoDB, you want the queries to be sharded consistently. For memcached, you want cache keys to consistently hash to the same server, at least while that server is up. For MySQL and Apache Thift, typically any server in the high availability set can receive a query. Why don’t more client libraries implement high availability? For example, I could not find a MySQL or Apache Thrift client that did. For those services, it’s commonly recommended to run an internal load balancer in between the client and the servers.
Given a datastore where no high availability client library exists, should you write your own, or use a dedicated load balancer? At first blush, it would seem that just randomly choosing a server from a list would get you basic load balancing. For high availability, you would additionally need to intelligently remove servers from the list when they are down, and add them in again when they come back up. This is known as health checking, and it’s built-in to any decent load balancer. This should be your first hint that you’re embarking on re-inventing the wheel.
Let’s look at HAProxy in particular, an excellent open-source load balancer. Here is a list of the kinds of features that I have found useful over the years. I certainly would not want to have to write all these myself!
- Header inspection
- Header re-writing
- Buffering
- Least-connection routing
- ACLs
- Logging
- SSL Proxy
- Compression
- Timeouts
- Configurable from a simple text file
- Metrics!
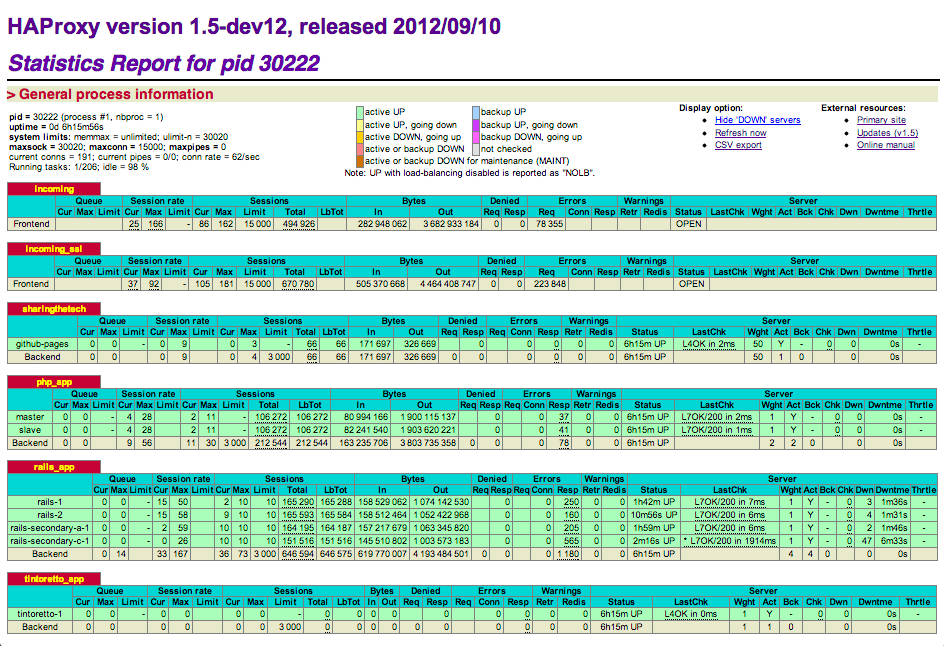
There is also a fundamental advantage to having a centralized load balancer versus distributed load balancing logic. It allows you to make routing decisions based on the activity of the aggregated cluster, not just your individual node. For example, you can enforce that a given node never receives more than X concurrent connections across all clients.
In addition, like any good open-source project, HAProxy is well documented. It’s also re-usable, as you built knowledge about how to deploy it for various solutions, you’re leveraging what you’re already learned about it to provide even better solutions.
The downside is that while client library high availability removes single points of failure from the system, with a dedicated load balancer you have to implement high availability of the load balancer itself. Typically, this is done via shared IPs and heartbeat failover.