
Two (more) Weeks in QA
Due to our regular QA engineer being out on vacation, I once again has the opportunity to do a tour of duty in QA. This time, for a big mobile release. I previously wrote about a similar experience eight (!) years ago, so I thought I would once again write down some reflections.
Web vs Mobile
Last time, I was testing a web product. This time, it was a mobile app. That turned out to make a big difference. For one thing, I spent a lot more time manually testing on various physical phones. Our app is on both Android and iOS, so that’s at least two devices for every test. But you also have to test on older slower phones, phones on older versions of the operating system, etc. Plus it’s all via touch interfaces. It ends up being more time than testing web features for a few browsers.
More Documentation Time
This time I spent a lot more time updating test plans. Because we have to test on so many phones, we have an outsourced QA team for even more manual testing horsepower. While I may test on five or six phones, I can send a test plan over to a remote team to run it on fifteen to twenty phones.
The existing documentation turned out to be very useful. Not only did it remind me about a bunch of test cases I would have forgotten about, but it had all kinds of hints about the most efficient way to test a specific case.
Communication
Because it was a big release, I spent a bunch of time coming up with daily reports of whether we were on track for launch. At a high level, I wanted to communicate how many bugs we had, new bugs we had discovered that day, any blockers for release and what step on our release schedule we were on.
But I also made some fun graphs!
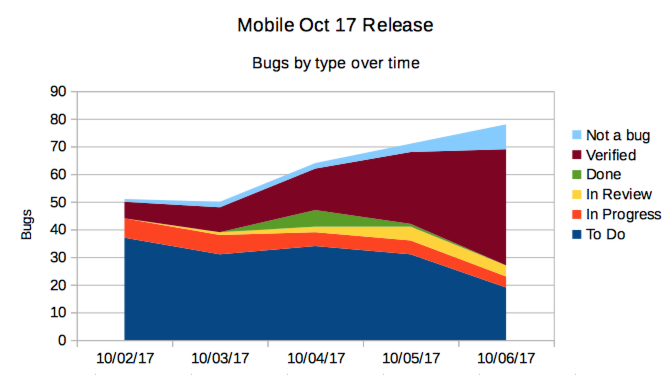
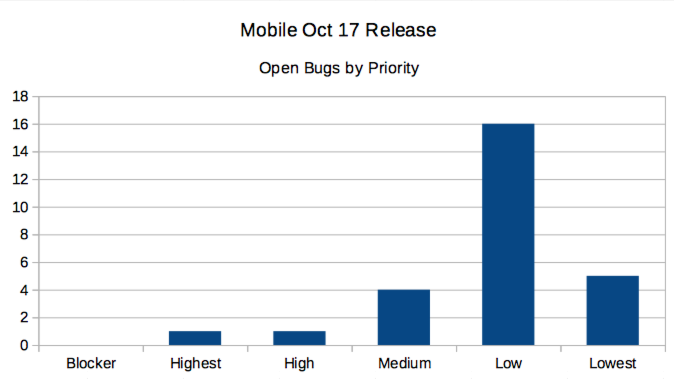
Triage & Troubleshooting
This time, I got more involved in triaging new bugs. Not just reproducing them and writing a good bug report, but also setting priority. This turned out to often involve discussions with both the product owner and the engineers. On more than a few bugs, we decided that while the severity of the bug was low to medium, we actually did not want to fix it now because we don’t have a good solution that doesn’t involve a medium sized refactor.
Similarly, we ended up having a lot of conversations about how to be more defensive in the code to prevent errors like the one in a particular bug report more generically. Some of these were also not feasible/wise to take on immediately. They went into the backlog.
What Was the Same
Once again, I was surprised my how many blocking issues I ran into just trying to get a build running well enough to test. We have most of the kinks worked out of our build pipeline, so there were not any problems getting a given build onto a phone. But I was blocked for days at a time on things like third party API integration staging environments being down. In one case, it took way too much time to discover that the breakage was related to a new network configuration in the office; we had forgotten to whitelist some IPs.