
Creating International CSV files with Python
You might assume that reading and writing files using the CSV format, being a simple and human-readable implementation, would be relatively pain free. You would be wrong. It turns out that even though there is a standard, many applications out there do not conform, or require their own additions and modifications. Most notable among the outliers is Microsoft Excel, which forces you to do some crazy things if you want to produce CSV files that can be read by any edition of Windows/Office, including international versions.
Yes, you heard me right. Whether you’re running the US or European version of Windows can effect whether you can seemlessly open a CSV file with commas as the delimiter. Apparently some countries prefer their comma delimited text to be delimited with semicolons. More on that later.
The name “CSV” indicates the use of the comma to separate data fields. Nevertheless, the term “CSV” is widely used to refer a large family of formats, which differ in many ways. For example, many so-called “CSV” files in fact use the tab character instead of comma (such files can be more precisely referred to as “TSV” for tab separated values); some implementations allow or require single or double quotation marks around some or all fields; and some reserve the very first record as a header containing a list of field names. The character set being used is undefined: some applications require a Unicode BOM to enforce Unicode interpretation - Wikipedia
Diacriticly Delicious
The first hurdle when producing international CSV files with Python is the csv module’s
lack of native unicode support:
The csv module doesn’t directly support reading and writing Unicode, but it is 8-bit-clean save for some problems with ASCII NUL characters. So you can write functions or classes that handle the encoding and decoding for you as long as you avoid encodings like UTF-16 that use NULs. UTF-8 is recommended.
Instead, they suggest that you use a a custom UnicodeWriter class.
class UnicodeWriter:
"""
A CSV writer which will write rows to CSV file "f",
which is encoded in the given encoding.
"""
def __init__(self, f, dialect=csv.excel, encoding="utf-8", **kwds):
# Redirect output to a queue
self.queue = cStringIO.StringIO()
self.writer = csv.writer(self.queue, dialect=dialect, **kwds)
self.stream = f
self.encoder = codecs.getincrementalencoder(encoding)()
def writerow(self, row):
self.writer.writerow([s.encode("utf-8") for s in row])
# Fetch UTF-8 output from the queue ...
data = self.queue.getvalue()
data = data.decode("utf-8")
# ... and reencode it into the target encoding
data = self.encoder.encode(data)
# write to the target stream
self.stream.write(data)
# empty queue
self.queue.truncate(0)
def writerows(self, rows):
for row in rows:
self.writerow(row)
However, even with this handy class, you will find that Excel 2007, 2010 and 2013 will fail to detect the UTF-8 encoding. I should note that Google Docs and LibreOffice have no problems detecting the encoding. If you’re using earlier versions of Excel, it’s even worse. Excel 97, 2000 and 2003 will simply fail to open the file at all unless you use the import wizard and manually specify the encoding.
Dropping Bombs
For the versions of Excel from the modern era, you need to explicitly denote the encoding using a BOM, or Byte Order Mark.
The byte order mark (BOM) is a Unicode character used to signal the endianness (byte order) of a text file or stream. It is encoded at U+FEFF byte order mark (BOM). BOM use is optional, and, if used, should appear at the start of the text stream. Beyond its specific use as a byte-order indicator, the BOM character may also indicate which of the several Unicode representations the text is encoded in.
Fun. I find that meditating on my own endianness is a very relaxing morning ritual. In any case, it’s fairly simple to write the UTF-8 BOM to the very start of the file:
import codecs
def __init__(self, f, dialect=csv.excel, encoding="utf-8", **kwds):
...
self.stream = f
self.stream.write(codecs.BOM_UTF8)
...Note: You need to write the BOM directly to the file buffer, and not via the UnicodeWriter.writer object, otherwise the BOM itself will be encoded as UTF-8, when it needs to be raw bytes.
Separating the Men from the Boys
It turns our that there is another insidious issue with international versions of Windows. There is actually a setting
in Windows Regional and Language
control panel called “List Separator”. In the US version of Windows, the default is a comma (,). In other locales,
specifically the European version, the default is often a semi-colon (;).
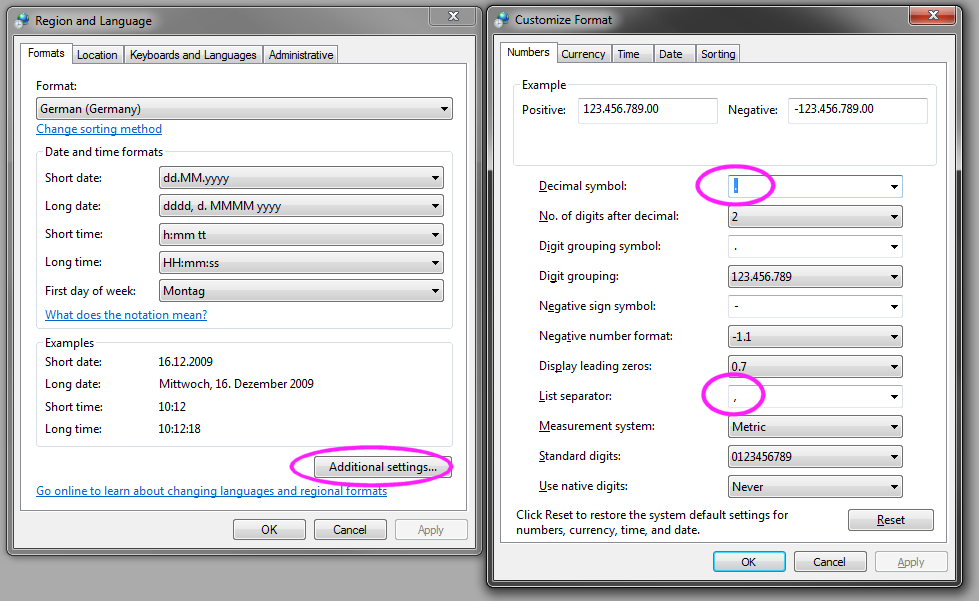
There are several hack solutions to this. The first is to tell all your European users to change their setting. The second is to save the file as a .txt file, and tell the users to choose “Open with Excel”, which will then run the import wizard and detect the delimiter. The third is to tell them to always use launch the import wizard manually, and not to simply double click on the file to open it.
The fourth, slightly less gross hack
to is put sep=, as the first line in your csv file, which will signal to Excel that you want to explicitly use commas as
the delimiter.
import os
def __init__(self, f, dialect=csv.excel, encoding="utf-8", **kwds):
...
self.stream.write('sep=,' + os.linesep)
...Note: this line will show up in most spreadsheet applications as the first line of your data. So users may have to manually delete the first two every time they start working with a file.
More Fun
After some more research, it turns out that Mac Excel simply does not support UTF-8 at all. So forget it ever working there.
Also, writing BOTH the BOM and the sep=, will cause Windows Excel to forget about the BOM
you just specified. So, you basically need to choose whether you want unicode characters to show up correctly, or
whether you want to have the columns separated automatically.